
LLMs Work. The Problem is Translation.
LLMs work very well. But there is a translation problem between LLMs and the environment that LLMs have to interact with (software and humans).

I have posted bits and pieces of my thinking on LLMs and AI agents. Here’s a longer piece on it to consolidate my ideas on the translation problem.
To understand why the problem with LLMs is in translation, we need to understand how LLMs work.
How LLMs Work
LLMs are trained on tokens, which are basically human languages translated to LLM language. For example, the sentence “I love you.” is translated into [40, 3047, 481, 13] for GPT-4o.
These numbers are token IDs, which are then converted into embeddings of higher dimensions, processed by the core transformer model of LLM at a even higher dimension to give output tokens, which may be [40, 3047, 481, 3101, 13], which are then translated back to human language, “I love you too.”
Here’s the model code snippet from nanoGPT to showing how this translation works in Python code:

Here’s the step-by-step process illustration of the process created by me:
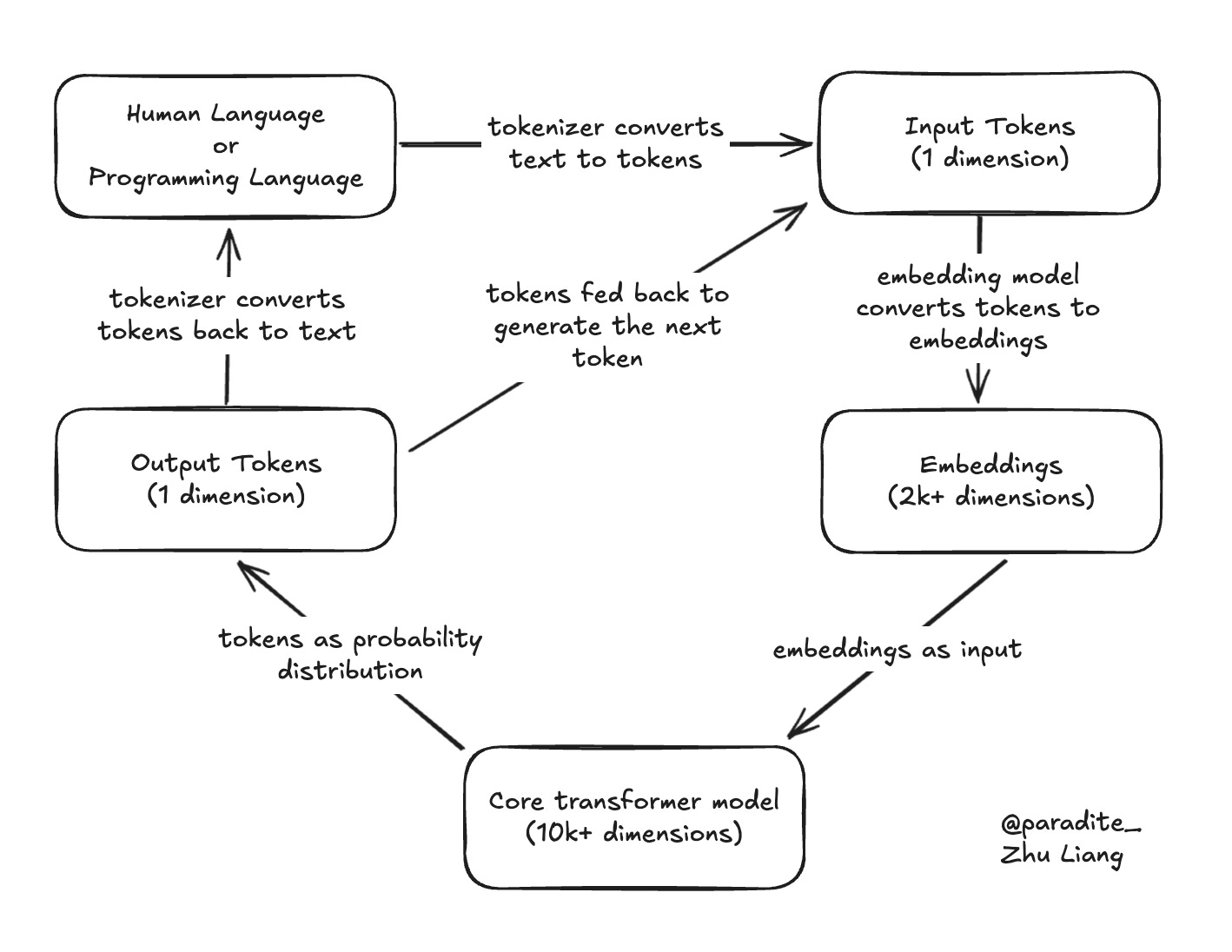
Let’s take a look at each step:
The conversion from human language or programming language to token IDs is handled by the tokenizer, which is a separate system from the core transformer model in LLM.
The conversion from token IDs to embeddings is handled by a smaller embedding model, which is part of the LLM, but not the core transformer model where the magic happens.
The core transformer model processes the embeddings to give output tokens.
The output tokens are translated back to human language or programming language by the tokenizer.
We don’t know the exact dimensions of SOTA models by OpenAI (GPT-5) and Anthropic (Claude Sonnet 4.5), but we can use DeepSeek V3 as reference. DeepSeek V3 embedding model has dimension of 2048, and core transformer model has dimension of 10944 each for the two dense layers and 1408 for each expert layer.
In summary, the core transformer model of LLMs, which is where most of the parameters are trained and stored as weights, is mainly in the higher dimensional space, not in the token space or embedding space.
Translation Problem
Now that we understand how LLMs work, we can see that there is a translation problem between LLMs and the environment that LLMs have to interact with (software and humans):
Most of LLM model operations are performed in the higher dimensional space, not in the token space. On the other hand, software and humans operate in human language and programming languages, which are translated to token IDs by the tokenizer.
So while model can come up with good answers in higher dimensions, when it comes to interacting with the environment, it has to translate the answers back to token IDs (single dimension), which is then translated back to human language and programming languages.
There are two translation layers in the process:
Between higher dimensions and token IDs
Between token IDs and human languages & programming languages
These two translation layers cause information loss and mismatch in precision, which are the source of hallucinations.
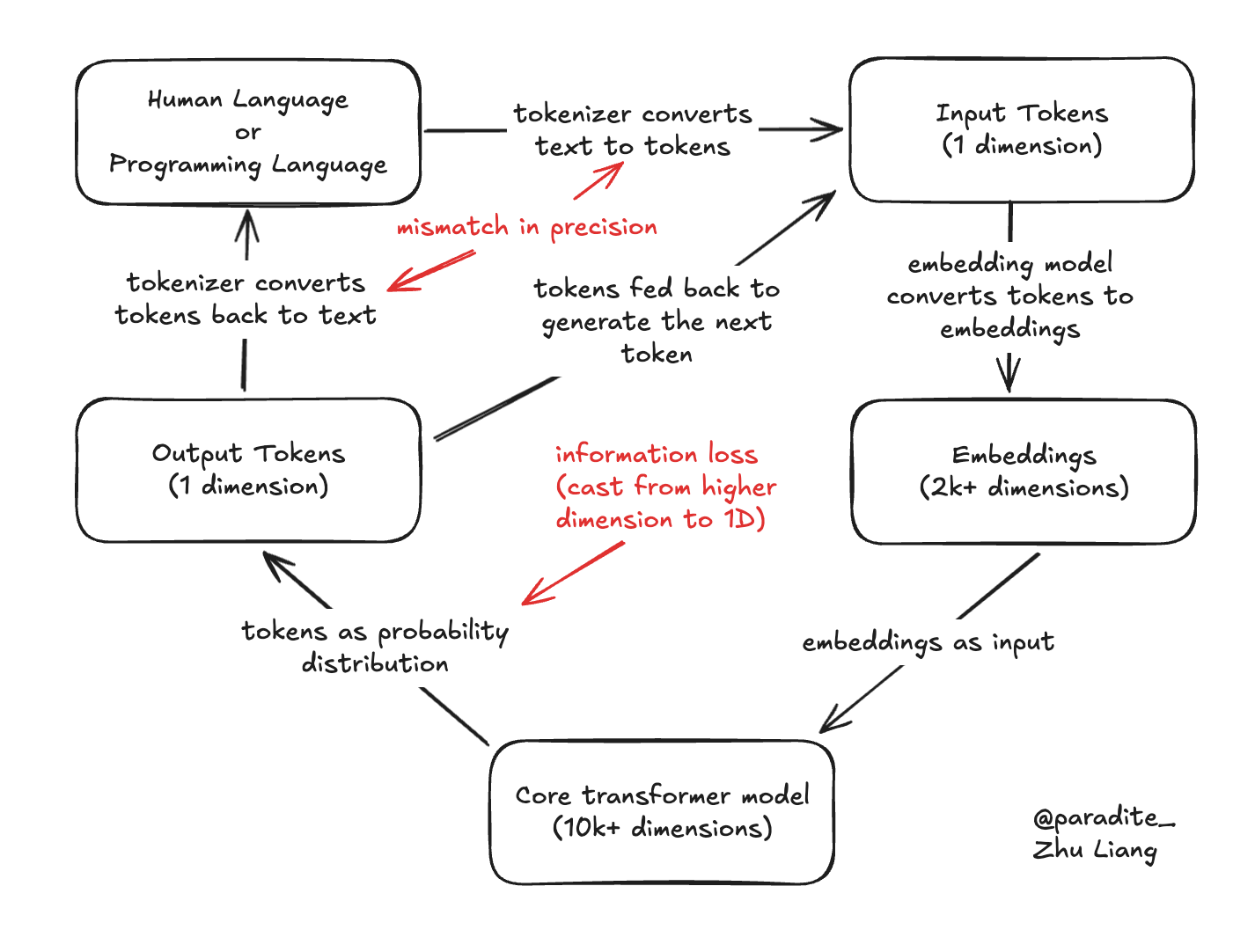
Information loss: The core transformer model needs to cast concepts from higher dimensions back to 1-dimensional token ID, which causes information loss. Furthermore, there is consistency requirements for human language, hindering the model’s ability to express ideas with the most suitable token ID, just because it was in a different human language.
Mismatch in precision: The tokens have different precision levels from human language (characters) and programming languages (symbols), which causes mismatch in precision. LLMs are trained with tokens as the basic units of input and output, and one token usually maps to several characters or symbols, so the model lacks understanding of characters and symbols.
It’s worth noting that the translation happens for both input and output. And this compounds the inaccuracy of the answers as the LLM processes new input tokens to generate new output tokens, especially in the case of autonomous AI agents where the loop can go on for very long time.
Examples of Translation Errors
How many Rs are in the word strawberry?
The famous “How many R are in the word strawberry?” example is a classic example of hallucination. The model first translates the word “strawberry” to token IDs, [302, 1618, 19772].
The problem is that the model does not see “strawberry” as a word composed of letters, but as 3 tokens. The basic unit of LLM processing is a token ID, but the basic unit of English language is a letter, and they don’t match one-to-one. Hence, it is difficult for the model to understand that the word “strawberry” is composed of 3 R’s, as all it sees is 3 tokens.
The newer models are able to answer this question correctly because of its massive pre-training data on English language, but ultimately, it is a translation problem between the language of humans and the language of LLMs.
Mixing of languages in model responses
Models, especially the ones from Chinese labs like DeepSeek and Qwen, often mix up English and Chinese in their responses. This is an example of translation issue between the language of humans and the language of LLMs.
For LLMs, they see token IDs and map them to concepts in higher dimensional space. For LLMs it does not really matter what human language the concepts are in.
In fact it is often the case where some concepts are better explained in one human language than the other, so it makes sense to use a mixture of languages when trying to cast higher dimensional concepts back to human language.
Seahorse emoji
LLMs can incorrectly say there is a seahorse emoji, just to realize that it can’t produce it. This is a translation error as well:
LLM cannot find a mapping from the seahorse concept in higher dimension to a set of tokens that capture this concept as an emoji. This is similar to how we sometimes find it hard to explain a concept from a foreign language in English.
How to Solve the Translation Problem
I believe there are several potential solutions to solve the translation problem:
Use a better way to capture real world concepts in higher dimensions (images and videos instead of text) for the models, to avoid information loss during translation.
Make programming languages more compatible with LLMs (e.g. align the precision level of the programming language to the tokenizer or the tokenizer to the precision level of the programming language).
Teach humans to be multilingual and understand concepts in multiple languages, so that LLMs do not need to be forced to output tokens in a specific language, causing information loss.
When humans, softwares and models all speak the same language, models will be much more effective than they are today.
That’s all for this post. I have a lot more thoughts on AI agents and AGI. But I really wanted to write on this topic first since I believe this is a blind spot for many people.
Let me know what you think by leaving a comment. More posts coming in the future!
Is the Deepseek-OCR Context Compression concept relevant to this? https://deepseek.ai/blog/deepseek-ocr-context-compression
I heard Karpathy respond that he feels it might make more sense to do away with tokens and process everything as images similar to how humans do.